One of the most common issues we run into when performing technical SEO audits for new clients concerns a website’s internal linking structure. A healthy internal linking structure establishes an efficient gateway for both users and search engines to navigate a website. They go onto establish the right site architecture and spread link equity throughout the pages of your site.
Top performing websites typically follow a category and subcategory approach as it allows link equity to spread throughout the entire site. It’s best practice to link more frequently to the pages that are most important to the business.
The main culprits we find that throw off a site’s linking structure are pages that are “hidden” or not linked to from other pages. This makes it almost impossible for crawlers to find and access these URLs. These pages that do not contain any internal links are also known as “orphan pages.”
Normally, Google finds URLs one of three ways: either by crawling the website, using an XML sitemap via Google Search Console, or through third party backlinks from other crawled pages on other sites. With orphan URLs, you restrict Google’s ability to discover these pages to these final two channels
To make matters worse, no authority will be passed to these pages if there are no internal links pointing to them. Adding internal links to these pages will help improve SEO visibility in the SERPs and ensure these pages are crawled more effectively.
Using Screaming Frog to Find Orphan URLS
One of the easiest ways to find Orphan URLs is to use the website crawler Screaming Frog. Screaming Frog crawls and analyzes key technical SEO elements from your website. It fetches analysis data by crawling links it finds on the page. However, your site’s orphan URLs will not be identified by Screaming Frog’s default settings as there are no internal links directing to them.
Fortunately, the Crawl Analysis feature helps find Orphan URLs by performing a post-crawl analysis by comparing your website crawl against your sitemap.
How to Enable Screaming Frog’s Crawl Analysis Feature
Go into Screaming Frog’s Configuration Settings (Configuration > Spider > Basic Tab), and check off all the boxes at the bottom of the Basic Tab. If your XML Sitemap isn’t listed in your Robots file or linked on your site, you can enter the XML Sitemap URL in the white field.
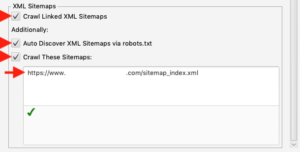
Click the “OK” button to save your settings and start the crawl. Remember that Screaming Frog won’t retroactively apply changed settings if you paused or finished a crawl. You must start a crawl from scratch if you want changes applied.
After your crawl is completed, click on “Crawl Analysis” from the top menu and hit start. The Crawl Analysis must be completed post-crawl. A second status bar will appear displaying when the analysis is 100% completed.

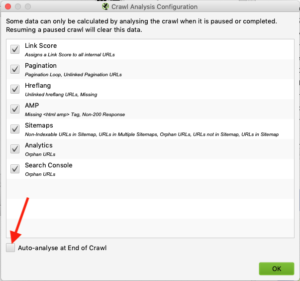
Alternatively, you can set the Crawl Analysis to run automatically after crawls are completed by ticking the “Auto-analyse at End of Crawl” box in the Crawl Analysis > Configure settings. You’ll still need an XML Sitemap to be crawled from our previous steps.
In the right-hand “Overview” pane, scroll down to the “Sitemaps” section. The Sitemaps section will filter results in the main window pane. Click on “Orphan URLs,” and you will find a list of pages that do not contain any internal links.

In the main window page, you’ll find a list of pages classified as orphan URLs. Screaming Frog gives you the option to export results in an Excel file for easier data analysis. This is preferred as you can sort by different page contents (HTML, Images, JavaScript, etc.).
Review the pages to see if they require amendment, noting that there might be some pages Screaming Frog found that don’t require amendment. From an indexing perspective, HTML pages would be our top concern as these are URLs we want crawled. Images and JavaScript would be of lower priority but should not be ignored.
Why Your Pages Are Being Listed as Orphan URLs
The most obvious is that there aren’t any internal links pointing to those pages. More often than not, companies end up omitting these pages because there wasn’t sufficient room to include them in category and subcategory menus.
If internal links are in fact present, there could be a bigger issue with how your page or links are being rendered. Review your Meta Robots Tags and Robots.txt file for any directives that are blocking these pages. Speak with your developer and find out if links are built with JavaScript instead of standard HTML links. Also be mindful that links inside Flash, Java, or iFrames are often inaccessible by crawlers.